20.3 Colli di Bottiglia nell'Accesso
I moderni sistemi hanno frequentemente la necessità di accedere ai dati in modo concorrente. Ad esempio, un grande server FTP o HTTP può avere migliaia di sessioni concorrenti e molteplici connessioni da 100 Mbit/s verso il mondo esterno, ben oltre il transfer rate (velocità di trasferimento) che la maggior parte dei dischi può sostenere.
I dischi odierni possono trasferire sequenzialmente dati fino a 70 MB/s, ma questo valore ha poca importanza in un ambiente dove molti processi indipendenti accedono al disco, in quanto raggiungerebbero solo una frazione di quella velocità. In questi casi è più interessante vedere il problema dal punto di vista del sottosistema dischi: il parametro importante è il carico che il trasferimento pone sul sottosistema, in altre parole il tempo per cui il trasferimento occupa i dischi necessari per lo stesso.
In ogni trasferimento da disco il drive deve prima posizionare le testine, poi aspettare che il primo settore passi sotto la testina di lettura e solo dopo può effettuare il trasferimento. Queste azioni possono essere considerate atomiche: non ha alcun senso interromperle.
Considera un tipico trasferimento di circa 10 kB: l'attuale generazione di dischi ad alte prestazioni può posizionare le testine in circa 3,5 ms. I dischi più veloci ruotano a 15.000 rpm, quindi la latenza media rotazionale (mezzo giro) è di 2 ms. A 70 MB/s, il trasferimento in sé occupa circa 150 μs, quasi nulla in confronto al tempo di posizionamento. In questo caso il transfer rate effettivo può scendere fino a poco oltre 1 MB/s e questo è chiaramente molto dipendente dalla dimensione del trasferimento.
La tradizionale e ovvia soluzione a questo collo di bottiglia è “più assi”: invece di usare un grande disco si usano molti piccoli dischi con la stessa dimensione totale. Ogni disco è capace di posizionarsi e trasferire dati indipendentemente quindi la velocità effettiva aumenta di un fattore vicino al numero di dischi usati.
L'esatto fattore di miglioramento è, ovviamente, più piccolo del numero di dischi: benché ogni disco sia capace di trasferire in parallelo non c'è modo di assicurare che le richieste siano distribuite uniformemente tra tutti i dischi. Inevitabilmente il carico su uno dei dischi è più alto che sugli altri.
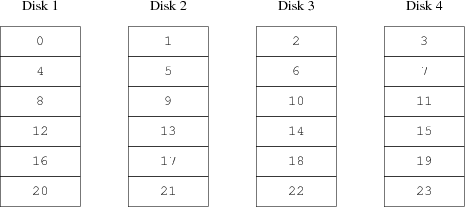
L'uniformità della distribuzione del carico sui dischi è fortemente dipendente dal modo in cui i dati sono condivisi tra i dischi stessi. Nella seguente discussione è conveniente pensare allo spazio di immagazzinamento come se fosse diviso in un gran numero di settori identificati da un indirizzo numerico, come pagine in un libro. Il metodo più ovvio è di dividere il disco virtuale in gruppi di settori consecutivi della dimensione dei dischi fisici e immagazzinarli in questa maniera, come strappare un grosso libro in piccole sezioni. Questo metodo è chiamato concatenazione e ha il vantaggio di non avere particolari richieste sulla dimensione degli specifici dischi. Funziona bene quando l'accesso al disco virtuale è ben ripartito tra tutto il suo spazio di indirizzamento. Quando l'accesso è concentrato in una piccola area il miglioramento è meno marcato. La Figura 20-1 illustra la sequenza in cui le unità di immagazzinamento sono allocate nell'organizzazione concatenata.
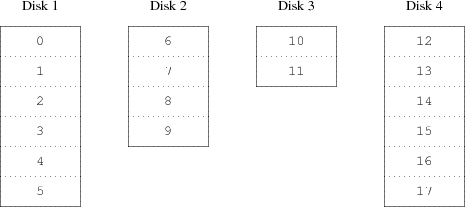
Un metodo alternativo è dividere lo spazio di indirizzamento in più piccole componenti di egual dimensione e immagazzinarle sequenzialmente su differenti dispositivi. Per esempio i primi 256 settori potrebbero essere immagazzinati sul primo disco, i seguenti 256 settori sul disco seguente e così via. Dopo aver immagazzinato i dati sull'ultimo disco il processo si ripete finché i dischi non sono pieni. Questo mappamento è chiamato striping (letteralmente "a bande") o RAID-0 [1]. Lo striping richiede qualche sforzo aggiuntivo per localizzare i dati e può causare carico di I/O aggiuntivo quando il trasferimento è distribuito tra vari dischi, ma aiuta il carico a essere ben distribuito tra i vari dischi. La Figura 20-2 illustra la sequenza in cui i blocchi di dati sono allocati nell'organizzazione in striping.